Outils¶
Performances¶
CPython¶
Faire un module python en C/C++ permet de bénéficier de la vitesse de ces derniers. Il a une véritable complexité associée à ce genre de montage, mais les bénéfices peuvent être importants; La doc dans la doc officielle python.
CFFI¶
Le principe : Aller chercher directement dans une librairie dynamique les fonctions dont on a besoin, par reconnaissance de signature de fonction.
Une petite mise en bouche sur le site de Sam&Max et la doc du projet.
Autre¶
Il est aussi possible de fonctionner avec Numba ou autre
Développement¶
virtualenv¶
Isolation de l’environnement python. On a cloné le binaire python, donc on ne
suit pas les mises à jours faites par le système. La librairie standard est
liée dynamiquement (symlink). On peut l’activer en faisant
virtualenv <dossier> puis source <dossier>/bin/activate.
pew¶
pew permet de créer un shell complet avec l’environnement de virtualenv.
pyvenv¶
À partir de python 3.3 le module venv permet de créer des environements
virtuels nativement
Packaging et déploiement¶
Doc officielle sur le packaging
Data¶
Pour ajouter des données tierces aux paquets la meilleure manière est d’ajouter un fichier
MANIFEST.in contenant la liste des fichiers à inclure (possibilité de globbing).
setuptools¶
Librairie permettant l’installation d’un package. La doc ici.
python setup.py develop
permet de faire un lien symbolique vers la librairie en cours de développement.
Pour générer les paquets de distribution, les commandes suivantes sont disponibles:
python setup.py sdist # Distribution des sources
python setup.py bdist # Distribution binaire sous forme d'egg (obsolète)
python setup.py bdist_wheel # Distribution binaire sous forme de wheel
Il est également possible de configurer setuptools pour utiliser un fichier
setup.cfg
en lieu et place de setup.py. Pour les projets de petite et moyenne envergure c’est souvent
plus adéquate.
pip¶
Utilitaire officiel de gestion des packets via le site PyPi.
Attention à la gestion des versions des dépendances, qui peuvent rentrer en conflit les unes par rapport aux autres.
Pour permettre d’installer simplement les dépendances d’une librairie, on peut
faire un fichier requirements.txt qu’on va remplir grâce à la commande
pip freeze > requirements.txt.
Mais il vaut mieux prendre ça comme base de travail, et l’améliorer un peu. Sinon les versions sont trop figées, et il n’est pas dit qu’on puisse facilement les retouver pour chaque librairie
# bien
pbr
Routes!=2.0,!=2.1,!=2.3.0,>=1.12.3;python_version=='2.7'
Routes!=2.0,!=2.3.0,>=1.12.3;python_version!='2.7'
# pas bien
cryptography=1.3.0
Pour installer une librairie en cours de développement (comme dans le cas de setuptools) on peut faire:
pip install -e .
twine¶
twine sert à envoyer vers PyPi les wheels et autres eggs.
Anaconda¶
Anaconda est un package installable sur Linux, OS X ou Windows contenant un intérpréteur python indépendant avec plus de 400 librairies incluses (matplotlib, numpy, pandas, etc.).
Une version light, Miniconda, permet de l’installer à peu près n’importe où.
Anaconda fait un peu tout en même temps: Environement virtuel, gestionnaire de paquets historisé, etc.
Import/export d’environement
De la même manière que pour pip, on peut créer un fichier qui permettra d’installer
toutes les dépendances nécessaires avec la commande conda list -e > conda-requirements.txt.
On peut ensuite installer les paquets dans un nouvel environnement via
conda install --file conda-requirements.txt.
On peut également déléguer l’installation de certains paquets à pip via le fichier
conda env export -n <name> > env.yml, puis tout installer via la commande
conda env create -f=env.yml. Cette méthode est à préférer.
Debug¶
import pdb; pdb.set_trace()
haffiche l’aidelaffiche le contexteaaffiche les variablesccontinuenligne suivante
Pour pouvoir débugger dans des sous-process générés par multiprocessing, on peut utiliser la
méthode suivante:
import sys
import pdb
class ForkedPdb(pdb.Pdb):
"""A Pdb subclass that may be used
from a forked multiprocessing child
"""
def interaction(self, *args, **kwargs):
_stdin = sys.stdin
try:
sys.stdin = open('/dev/stdin')
pdb.Pdb.interaction(self, *args, **kwargs)
finally:
sys.stdin = _stdin
ForkedPdb().set_trace()
Tests unitaires¶
doctest¶
def compute(nba, nbb):
"""Doc here
>>> compute(2,3)
5
>>> compute(2, '3')
Traceback (most recent call last):
...
TypeError: unsupported operand type(s) for +: 'int' and 'str'
>>> compute(5,5,2)
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: compute() takes exactly 2 arguments (3 given)
"""
return nba + nbb
python -m doctest -v <fichier.py>
On peut déporter les test dans un fichier *.txt pour ne pas trop surcharger la docstring.
Cf. Sam&Max
py.test¶
Très puissant outil de tests, mais fait un peu trop de trucs ésotériques au niveau des imports. Comme nosetest, il permet de lancer des tests issus d’autres suites (doctests, unittest, etc.).
Lire l’article de Sam&Max vachement complet, notamment la partie Outils qui liste les extensions existantes.
On peut citer :
capsys : permet de capturer les stdout/stderr
monkeypatch : Modification d’objets à la volée
tmpdir : Dossier temporaires
Il y a aussi une foule d’options sympa:
ne lancer que les tests dont le nom contient une expression
ignorer un path
tester aussi les doctest, unittest et nose
mocks¶
En modifiant les comportements à la vollée des fonctions et classes utilisées, on peut éviter d’avoir à mettre en place tout un environnement de test bien lourd.
Par exemple, si fait un utilitaire qui se connecte à une base de donnée, on peut simuler cette connexion et les réponses faites par la base sans en monter une de toute pièce. C’est moins couteux !
Bon du coup, c’est parfois un peu lourdingue à mettre en place, mais ça permet de vraiment aller tester dans les tréfonds.
Et l’inévitable lien vers l’article de Sam&Max qui explique tout.
Et quand les mocks ne font pas ce qu’on veut, c’est souvent qu’on fait pas ce qu’il faut
tox¶
Si j’ai bien compris, c’est un outil d’automatisation des tests, mais il faut creuser/vérifier ici.
Documentation¶
Sphinx est la clé !
Language extensible
Génére la liste des todo automatiquement.
L’idée c’est de piloter la structuration de la documentation.
litteralincludepour mettre des morceaux de codes dans le corps de page
automodulepermet d’aller chercher les docstring d’un module.
Profiling¶
Profiling de fonctions¶
Pour avoir le temps cumulé passé dans chaque fonction
python -m cProfile -s tottime fibo.py
Pour avoir le nombre d’appels de chaque fonction
python -m cProfile -o profile.pstats fibo.py
Sortie graphique
pip install gprof2dot
gprof2dot -f pstats profile.pstats | dot -Tpng -o output.png
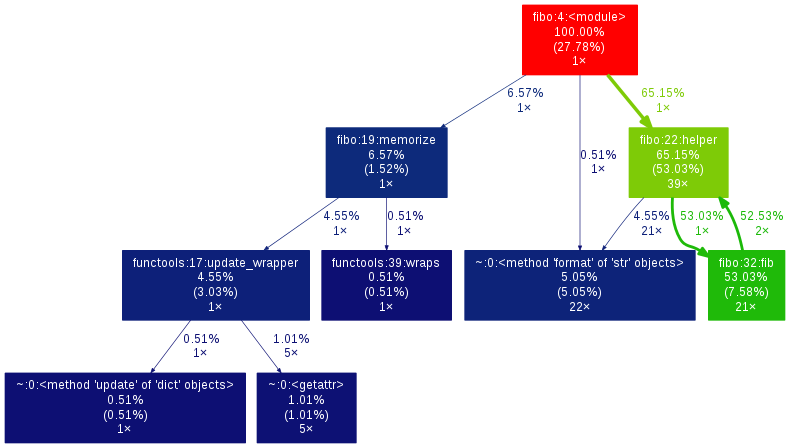
Une alternative qui fait de beau graphes est PyCallGraph
from pycallgraph import PyCallGraph
from pycallgraph.output import GraphvizOutput
with PyCallGraph(output=GraphvizOutput()):
# Code à profiler
Profiling ligne à ligne¶
$ pip install line_profiler
$ kernprof -v -l <script.py>
qui fait du profiling ligne par ligne et fournit également le décorateur
@profile à utiliser sur les fonctions qu’on souhaite profiler.
Il y a aussi
pip install memory_profiler
Lui aussi fournit un décorateur @profile.
Par contre ce n’est pas super précis, parce que python n’a que des références.
Ça ne correspond donc pas vraiment à ce qui est fait par python en mémoire.
Note
ça ne remplacera pas gdb pour la détection de fuites.
Temps d’exécution¶
La librairie timeit permet de mesurer les temps d’exécutions de différentes
fonction
import timeit
def func_a()
# ...
def func_b()
# ...
print(timeit.timeit('func_a()', globals=globals()))
print(timeit.timeit('func_b()', globals=globals()))
Autre¶
Les outils comme flake8 ou pep8 permettent de vérifier la conformité du code à la PEP 8.
radon permet de se faire une idée de la complexitée du code et de sa maintenabilité.